

CockroachDB — это база данных OLTP специализированная для обслуживания высокопроизводительных запросов, которые читают или записывают небольшое количество строк. По мере того как мы стали более активно использовать, мы обнаружили, что клиенты не получают ожидаемой производительности от аналитических запросов, которые читают много строк, таких как большие сканы, объединения или объединения. В апреле 2018 года мы начали серьезно изучать, как повысить производительность этих типов запросов в CockroachDB, и начали работу над новым механизмом выполнения SQL. В этом сообщении в блоге мы используем пример кода, чтобы обсудить, как мы создали новый движок и почему он приводит к четырехкратному повышению скорости по сравнению с отраслевым стандартом.
Базы данных OLTP, включая CockroachDB, хранят данные в последовательных строках на диске и обрабатывают запросы по одной строке за раз. Этот шаблон оптимален для обслуживания небольших запросов с высокой пропускной способностью и низкой задержкой, поскольку данные в строках хранятся непрерывно, что делает более эффективным доступ к нескольким столбцам из одной строки. Современные базы данных OLAP с другой стороны, обычно лучше справляются с большими запросами и имеют тенденцию хранить данные в смежных столбцах и работать с этими столбцами, используя концепцию под названием векторизованное исполнение . Использование векторизованной обработки в исполнительном механизме позволяет более эффективно использовать современные процессоры, изменяя ориентацию данных (от строк к столбцам), чтобы извлечь больше пользы из кэша ЦП и конвейеров глубоких инструкций, работая с пакетами данных за один раз.
В нашем исследовании векторизованного исполнения мы натолкнулись на MonetDB / X100: Hyper-pipelining Query Execution документ, в котором описываются недостатки производительности при последовательном выполнении вулканов. модель на которой был построен оригинальный механизм исполнения CockroachDB. При выполнении запросов к большому количеству строк механизм выполнения, ориентированный на строки, платит высокую цену за интерпретацию и накладные расходы на оценку для каждого кортежа и не в полной мере использует преимущества современных процессоров. Учитывая архитектуру хранения значения ключа CockroachDB, мы знали, что не можем хранить данные в столбчатом формате, но нам было интересно, можно ли преобразовать строки в пакеты столбчатых данных после чтения их с диска, а затем передать эти пакеты в векторизованный механизм исполнения, улучшит производительность достаточно, чтобы оправдать создание и поддержание нового механизма исполнения.
Чтобы количественно оценить улучшения производительности и проверить идеи, изложенные в статье, мы создали прототип векторизованного механизма исполнения который дал некоторые впечатляющие результаты. В этом посте в стиле учебника мы подробнее рассмотрим, как эти улучшения производительности выглядят на практике. Мы также демонстрируем, почему и как мы используем генерацию кода, чтобы облегчить бремя обслуживания механизма векторизованного исполнения. Мы возьмем пример запроса, проанализируем его производительность в игрушечном, поочередном механизме выполнения, а затем исследуем и реализуем улучшения, основанные на идеях, предложенных в статье MonetDB / x100. Код, упомянутый в этом посте, находится в https://github.com/asubiotto/vecdeepdive поэтому не стесняйтесь просматривать, изменять и / или запускать код и тесты, пока Вы следуете за собой.
Содержание статьи
Что в операторе SQL?
Чтобы обеспечить некоторый контекст, давайте посмотрим, как CockroachDB выполняет простой запрос SELECT price * 0.8 FR инвентаризации выданный вымышленным розничным клиентом, который хочет вычислить скидку для каждого элемента в ее инвентаре. Независимо от того, какой механизм выполнения используется, этот запрос анализируется, преобразуется в абстрактное синтаксическое дерево (AST) оптимизируется и затем выполняется. Выполнение, независимо от того, распределено ли оно между всеми узлами в кластере или выполняется локально, может рассматриваться как цепочка манипуляций с данными, каждая из которых играет определенную роль, которую мы называем операторами. В этом примере запроса поток выполнения будет выглядеть следующим образом:
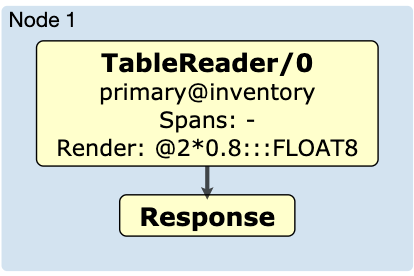
Вы можете создать диаграмму физического плана, выполнив EXPLAIN (DISTSQL) в запросе. Как видите, поток выполнения этого запроса относительно прост. Оператор TableReader считывает строки из таблицы инвентаризации и затем выполняет выражение рендеринга постобработки, в данном случае умножение на постоянное значение с плавающей запятой. Давайте сосредоточимся на выражении рендеринга, так как именно часть потока выполняет большую часть работы.
Вот код, который выполняет это выражение рендеринга в оригинальном, ориентированном на строки механизме выполнения, используемом в CockroachDB (некоторый код здесь опущен для простоты):
func (expr * BinaryExpr) Eval (ctx * EvalContext) (Datum, error) {
left, err: = expr.Left. (TypedExpr) .Eval (ctx)
если ошибаться! = ноль {
вернуть ноль, ошибаться
}
правильно, err: = expr.Right. (TypedExpr) .Eval (ctx)
если ошибаться! = ноль {
вернуть ноль, ошибаться
}
вернуть expr.fn.Fn (ctx, слева, справа)
}
Левая и правая части двоичного выражения ( BinaryExpr ) являются значениями, заключенными в интерфейс Datum . BinaryExpr вызывает expr.fn.Fn с обоими из них в качестве аргументов. В нашем примере таблица инвентаризации имеет ценовую колонку FLOAT поэтому Fn :
Fn: func (_ * EvalContext, левая точка отсчета, правая точка отсчета) (точка отсчета, ошибка) {
вернуть NewDFloat (* left. (* DFloat) * * right. (* DFloat)), ноль
}
Для выполнения умножения значения Datum необходимо преобразовать в ожидаемый тип. Если бы вместо этого мы создали ценовой столбец типа DECIMAL мы бы преобразовали 0,8 в DECIMAL и затем построили ] BinaryExpr с другим Fn предназначенным для умножения DECIMAL s.
Теперь у нас есть специальный код для умножения каждого типа, но нет необходимости беспокоиться об этом TableReader . Перед выполнением запроса база данных создает план запроса, в котором указан правильный Fn для типа, с которым мы работаем. Это упрощает код, поскольку нам нужно только написать специализированный код в качестве реализации интерфейса. Это также делает код менее эффективным, так как каждый раз, когда мы умножаем два значения вместе, нам нужно динамически разрешать, который Fn вызывать, приводить значения интерфейса к конкретным значениям типа, с которыми мы можем работать, и затем преобразовывать результат возвращается к значению интерфейса.
Бенчмаркинг простого оператора
Насколько дорог этот кастинг, правда? Чтобы найти ответ на этот вопрос, давайте возьмем похожий, но более простой пример игрушки:
Тип базового интерфейса {}
// Int реализует интерфейс Datum.
Тип Int struct {
int64
}
func mulIntDatums (a Datum, b Datum) Datum {
aInt: = a. (Int) .int64
bInt: = b. (Int) .int64
return Int {int64: aInt * bInt}
}
// ...
func (m mulOperator) next () [] Datum {
row: = m.input.next ()
если строка == ноль {
вернуть ноль
}
для _, c: = range m.columnsToMultiply {
строка [c] = m.fn (строка [c]m.arg)
}
возвратный ряд
}
Это одиночный оператор, не зависящий от типа, который может обрабатывать умножение произвольного числа столбцов на постоянный аргумент. Представьте, что вход возвращает строки из таблицы. Чтобы добавить поддержку DECIMAL s, мы можем просто добавить другую функцию, которая умножает DECIMAL s на подпись mulFn .
Мы можем измерить производительность этого кода, написав эталонный тест ( см. В нашем репо ). Это даст нам представление о том, как быстро мы можем умножить большое количество строк Int на постоянный аргумент. Инструмент benchstat сообщает нам, что для этого требуется около 760 микросекунд:
$ go test -bench «BenchmarkRowBasedInterface $» -count 10> tmp && benchstat tmp && rm tmp
имя время / опера
RowBasedInterface-12 760 мкс ± 15%
Поскольку на данном этапе нам не с чем сравнивать производительность, мы не знаем, медленная она или нет.
Мы будем использовать эталон «скорость света», чтобы лучше понять относительную скорость этой программы. Тест скорости света измеряет выполнение минимально необходимой работы для выполнения операции. В данном случае мы действительно умножаем 65 536 int64 с на 2. Результатом выполнения этого эталонного теста является:
$ go test -bench "SpeedOfLight" -count 10> tmp && benchstat tmp && rm tmp
имя время / опера
SpeedOfLight-12 19,0 мкс ± 6%
Эта простая реализация примерно в 40 раз быстрее, чем наш предыдущий оператор!
Чтобы попытаться выяснить, что происходит, давайте запустим профиль процессора в BenchmarkRowBasedInterface и сосредоточимся на mulOperator . Мы можем использовать опцию -o чтобы получить исполняемый файл, который позволит нам разобрать функцию с помощью команды disasm в pprof . Как мы увидим ниже, эта команда даст нам сборку, в которую компилируется наш исходный код Go, а также приблизительное время процессора для каждой инструкции. Во-первых, давайте используем команды top и list для поиска медленных частей кода.
$ go test -bench "BenchmarkRowBasedInterface $" -cpuprofile cpu.out -o row_based_interface
...
$ go инструмент pprof ./row_based_interface cpu.out
(pprof) focus = mulOperator
(pprof) верх
Активные фильтры:
фокус = mulOperator
Показано, что на узлы приходится 1,99 с, 88,05% от общего числа 2,26 с.
Отбросил 15 узлов (включая <= 0,01 с)
Показаны 10 лучших узлов из 12
плоская квартира% сумма% включая диплом%
0,93 с 41,15% 41,15% 2,03 с 89,82% _ ~ / scratch / vecdeepdive.mulOperator.next
0,47 с 20,80% 61,95% 0,73 с 32,30% _ ~ / scratch / vecdeepdive.mulIntDatums
0,36 с 15,93% 77,88% 0,36 с 15,93% _ ~ / scratch / vecdeepdive. (* TableReader) .next
0,16 с 7,08% 84,96% 0,26 с 11,50% runtime.convT64
0,07 с 3,10% 88,05% 0,10 с 4,42% runtime.mallocgc
0 0% 88.05% 2.03s 89.82% _ ~ / scratch / vecdeepdive.BenchmarkRowBasedInterface
0 0% 88,05% 0,03 с 1,33% времени выполнения. (* Mcache) .nextFree
0 0% 88,05% 0,02 с 0,88% времени выполнения. (* Mcache) .refill
0 0% 88,05% 0,02 с 0,88% времени выполнения. (* Mcentral) .cacheSpan
0 0% 88,05% 0,02 с 0,88% времени выполнения. (* Mcentral) .grow
(pprof) список следующий
ROUTINE ======================== _ ~ / scratch / vecdeepdive.mulOperator.next в ~ / scratch / vecdeepdive / row_based_interface.go
930 мс 2,03 с (плоский, диплом) 89,82% от общего
, , 39:
60ms 60ms 40: func (m mulOperator) next () [] Datum {
120 мс 480 мс 41: строка: = m.input.next ()
50 мс 50 мс 42: если строка == ноль {
, , 43: вернуть ноль
, , 44:}
250 мс 250 мс 45: для _, c: = диапазон m.columnsToMultiply {
420ms 1.16s 46: строка [c] = m.fn (строка [c]m.arg)
, , 47:}
30 мс 30 мс 48: обратный ряд
, , 49:}
, , 50:
Мы видим, что из 2030 мс mulOperator тратит 480 мс получая строки со входа, и 11606 [19459] выполняя умножение. 420 мс из них тратятся в в следующем прежде чем даже вызвать m.fn (левый столбец - это плоское время, то есть время, проведенное на этой линии, в то время как правый столбец - совокупное время, которое также включает время, потраченное на функцию, вызываемую в этой строке). Поскольку кажется, что большая часть времени уходит на умножение аргументов, давайте подробнее рассмотрим mulIntDatums :
(pprof) список mulIntDatums
Итого: 2,26 с
ROUTINE ======================== _ ~ / scratch / vecdeepdive.mulIntDatums в ~ / scratch / vecdeepdive / row_based_interface.go
470мс 730мс (квартира, диплом) 32,30% от общего числа
, , 10:
70ms 70ms 11: func mulIntDatums (a Datum, b Datum) Datum {
20 мс 20 мс 12: aInt: = a. (Int) .int64
90мс 90мс 13: bInt: = b. (Int) .int64
290 мс 550 мс 14: return Int {int64: aInt * bInt}
, , 15:}
Как и ожидалось, большая часть времени, проведенного в mulIntDatums находится на линии умножения. Давайте подробнее рассмотрим, что здесь происходит, используя команду disasm (disassemble) (некоторые инструкции опущены):
(pprof) disasm mulIntDatums
, , 1173491: MOVQ 0x28 (SP), AX; row_based_interface.go: 12
20 мс 20 мс 1173496: тип LEAQ. * + 228800 (SB), CX; _ ~ / scratch / vecdeepdive.mulIntDatums row_based_interface.go: 12
, , 117349d: CMPQ CX, AX; row_based_interface.go: 12
, , 11734a0: JNE 0x1173505
, , 11734a2: MOVQ 0x30 (SP), AX
, , 11734a7: MOVQ 0 (AX), AX
90 мс 90 мс 11734aa: MOVQ 0x38 (SP), DX; _ ~ / scratch / vecdeepdive.mulIntDatums row_based_interface.go: 13
, , 11734af: CMPQ CX, DX; row_based_interface.go: 13
, , 11734b2: JNE 0x11734e9
, , 11734b4: MOVQ 0x40 (SP), CX
, , 11734b9: MOVQ 0 (CX), CX
70мс 70мс 11734bc: IMULQ CX, AX; _ ~ / scratch / vecdeepdive.mulIntDatums row_based_interface.go: 14
60 мс 60 мс 11734c0: MOVQ AX, 0 (SP)
90 мс 350 мс 11734c4: CALL runtime.convT64 (SB)
Удивительно, но только 70 мс тратится на выполнение инструкции IMULQ которая в конечном итоге выполняет умножение. Большая часть времени тратится на вызов convT64 который представляет собой пакетную функцию Go runtime которая используется (в данном случае) для преобразования типа Int в Базовый интерфейс .
Разобранное представление функций предполагает, что большая часть времени, затрачиваемого на умножение значений, преобразует аргументы из Datum s в Int s и результат из ] Int назад к Datum .
Использование типов бетона
Чтобы избежать издержек этих преобразований, нам нужно работать с конкретными типами. Это сложная ситуация, так как механизм исполнения, который мы обсуждали, использует интерфейсы, чтобы не зависеть от типа. Без использования интерфейсов каждый оператор должен знать о типе, с которым он работает. Другими словами, нам нужно было бы реализовать оператор для каждого типа.
К счастью, у нас есть предварительное исследование команды MonetDB, которое поможет нам. Учитывая их работу, мы знали, что боль, вызванная удалением интерфейсов, будет оправдана огромными потенциальными улучшениями производительности.
Позже мы рассмотрим, как мы справились с использованием операторов с конкретным типом, чтобы избежать типов типов по соображениям производительности, не жертвуя всеми возможностями сопровождения, которые дает использование интерфейсов Go, не зависящих от типа. Во-первых, давайте посмотрим, что заменит интерфейс Datum :
тип T int
const (
// Int64Type является значением типа int64
Int64Type T = йота
// Float64Type является значением типа float64
Float64Type
)
type TypedDatum struct {
т т
int64 int64
float64 float64
}
Тип TypedOperator interface {
next () [] TypedDatum
}
Элемент Datum теперь имеет поле для каждого возможного типа, который он может содержать, вместо того, чтобы иметь отдельные реализации интерфейса для каждого типа. Существует дополнительное поле enum, которое служит маркером типа, поэтому, когда нам это нужно, мы можем проверить тип данных, не делая никаких дорогостоящих утверждений типа. Этот тип использует дополнительную память из-за наличия поля для каждого типа, хотя только один из них будет использоваться одновременно. Это может привести к неэффективности кэша ЦП, но в этом разделе мы пропустим эти проблемы и сосредоточимся на рассмотрении накладных расходов при интерпретации интерфейса. В следующем разделе мы более подробно обсудим неэффективность и рассмотрим ее.
mulInt64Operator теперь будет выглядеть так:
func (m mulInt64Operator) next () [] TypedDatum {
row: = m.input.next ()
если строка == ноль {
вернуть ноль
}
для _, c: = range m.columnsToMultiply {
строка [c] .int64 * = m.arg
}
возвратный ряд
}
Обратите внимание, что умножение теперь на месте. Запуск теста с этой новой версией показывает почти двукратное увеличение скорости.
$ go test -bench "BenchmarkRowBasedTyped $" -count 10> tmp && benchstat tmp && rm tmp
имя время / опера
RowBasedTyped-12 390 мкс ± 8%
Однако теперь, когда мы пишем специализированные операторы для каждого типа, объем кода, который мы должны написать, почти удвоился, и, что еще хуже, этот код нарушает принцип удобства сохранения DRY ( ] D on't R epeat Y ). Ситуация кажется еще хуже, если учесть, что в реальном движке баз данных будет гораздо больше, чем два типа поддержки. Если бы кто-то немного изменил функциональность умножения (например, добавив обработку переполнения), ему пришлось бы переписать каждый отдельный оператор, что утомительно и подвержено ошибкам. Чем больше типов, тем больше работы нужно выполнить для обновления кода.
Генерация кода с помощью шаблонов
К счастью, есть инструмент, который мы можем использовать, чтобы уменьшить эту нагрузку и сохранить хорошие рабочие характеристики при работе с конкретными типами. Шаблонный движок Go позволяет нам написать шаблон кода, который, немного поработав, может заставить наш редактор работать с ним как с обычным файлом Go. Мы должны использовать шаблонизатор, потому что версия Go, которую мы используем в данный момент, не поддерживает универсальные типы. Шаблонные операторы умножения будут выглядеть следующим образом (полный код шаблона находится в row_based_typed_tmpl.go ):
// {{/ *
Тип _GOTYPE interface {}
// _MULFN присваивает результат умножения первого и второго
// операнд к первому операнду.
func _MULFN (_ TypedDatum, _ interface {}) {
паника («не звонить из не шаблонного кода»)
}
// * /}}
// {{ ассортимент .}}
Тип mul_TYPEOperator struct {
ввод TypedOperator
arg _GOTYPE
columnsToMultiply [] int
}
func (m mul_TYPEOperator) next () [] TypedDatum {
row: = m.input.next ()
если строка == ноль {
вернуть ноль
}
для _, c: = range m.columnsToMultiply {
_MULFN (строка [c]м.арг)
}
возвратный ряд
}
// {{ конец }}
Прилагаемый код для генерации полного файла row_based_typed.gen.go находится в row_based_type_gen.go . Этот код выполняется путем запуска go run. для запуска функции main () в generate.go (здесь для краткости опущено). Генератор будет перебирать фрагмент и заполнять шаблон конкретной информацией для каждого типа. Обратите внимание, что есть предварительный шаг, необходимый для того, чтобы считать файл row_based_typed_tmpl.go допустимым Go. В шаблоне мы используем токены, которые являются действительными Go (например, _GOTYPE и _MULFN). Объявления этих токенов заключены в комментарии к шаблону и удалены в окончательном сгенерированном файле.
Например, функция умножения ( _MULFN ) преобразуется в вызов метода с теми же аргументами:
// Заменить все функции.
mulFnRe: = regexp.MustCompile (`_MULFN ((. *), (. *) )`)
s = mulFnRe.ReplaceAllString (s, `{{.MulFn" $ 1 "" $ 2 "}}`)
MulFn вызывается при выполнении шаблона, а затем возвращает код Go для выполнения умножения в соответствии с информацией о типе. Посмотрите на окончательный сгенерированный код в row_based_typed.gen.go.
У шаблонного подхода, который мы взяли, есть некоторые нюансы, и, конечно, он не очень гибок в реализации. Тем не менее, это критическая часть реального векторизованного механизма исполнения, который мы создали в CockroachDB, и его было достаточно просто собрать, не отвлекаясь на создание надежного предметно-ориентированного языка. Теперь, если мы хотим добавить функциональность или исправить ошибку, мы можем один раз изменить шаблон и сгенерировать код для всех операторов. Теперь, когда код стал немного более управляемым и расширяемым, давайте попробуем еще больше повысить производительность.
ПРИМЕЧАНИЕ. Чтобы облегчить чтение кода в оставшейся части этого блога, мы не будем использовать генерацию кода для следующих операций перезаписи оператора.
Пакетная обработка дорогих вызовов
Повторение нашего предыдущего процесса сравнения показывает нам несколько полезных следующих шагов.
$ go test -bench "BenchmarkRowBasedTyped $" -cpuprofile cpu.out -o row_typed_bench
$ go tool pprof ./row_typed_bench cpu.out
(pprof) список следующий
ROUTINE ======================== _ ~ / scratch / vecdeepdive.mulInt64Operator.next в ~ / scratch / vecdeepdive / row_based_typed.gen.go
1,26 с 1,92 с (плоский, диплом) 85,71% от общего числа
, , 8: Тип ввода Оператор
, , 9: arg int64
, , 10: columnsToMultiply [] int
, , 11:}
, , 12:
180мс 180мс 13: func (m mulInt64Operator) next () [] TypedDatum {
170мс 830мс 14: строка: = m.input.next ()
, , 15: если строка == ноль {
, , 16: вернуть ноль
, , 17:}
330 мс 330 мс 18: для _, c: = диапазон m.columnsToMultiply {
500 мс 500 мс 19: строка [c] .int64 * = m.arg
, , 20:}
80мс 80мс 21: обратный ряд
, , 22:}
В этой части профиля показано, что примерно половина времени, потраченного на функцию mulInt64Operator.next расходуется на вызов m.input.next () (см. Строку 13 выше). Это не удивительно, если мы посмотрим на нашу реализацию (* typedTableReader) .next () ; это много кода только для перехода к следующему элементу в срезе. Мы не можем оптимизировать слишком много о typedTableReader поскольку нам нужно сохранить возможность связывать его с любым другим оператором SQL, который мы можем реализовать. Но есть еще одна важная оптимизация, которую мы можем сделать: вместо того, чтобы вызывать следующую функцию по одному разу для каждой строки, мы можем получить пакет строк и работать со всеми из них одновременно, не слишком меняя настройки в (* typedTableReader) .next . Мы не можем просто получить все строки одновременно, потому что некоторые запросы могут привести к огромному набору данных, который не помещается в памяти, но мы можем выбрать достаточно большой размер пакета.
Благодаря этой оптимизации у нас есть операторы, подобные приведенным ниже. Еще раз, полный код для этой новой версии опущен, так как есть много стандартных изменений. Полные примеры кода можно найти в row_based_typed_batch.go .
Тип mulInt64BatchOperator struct {
ввод TypedBatchOperator
arg int64
columnsToMultiply [] int
}
func (m mulInt64BatchOperator) next () [] [] TypedDatum {
строки: = m.input.next ()
если строки == ноль {
вернуть ноль
}
для _, строка: = диапазон строк {
для _, c: = range m.columnsToMultiply {
row [c] = TypedDatum {t: Int64Type, int64: row [c] .int64 * m.arg}
}
}
вернуть строки
}
type typedBatchTableReader struct {
curIdx int
строки [] [] TypedDatum
}
func (t * typedBatchTableReader) next () [] [] TypedDatum {
if t.curIdx> = len (t.rows) {
вернуть ноль
}
endIdx: = t.curIdx + batchSize
if endIdx> len (t.rows) {
endIdx = len (t.rows)
}
retRows: = t.rows [t.curIdx:endIdx]
t.curIdx = endIdx
возврат ретроу
}
С этим пакетным изменением тесты запускаются почти в 3 раза быстрее (и в 5,5 раз быстрее, чем исходная реализация):
$ go test -bench "BenchmarkRowBasedTypedBatch $" -count 10> tmp && benchstat tmp && rm tmp
имя время / опера
RowBasedTypedBatch-12 137µs ± 77%
Данные, ориентированные на столбцы
Но мы все еще далеки от того, чтобы приблизиться к нашей производительности «скорости света», составляющей 19 микросекунд на операцию. Новый профиль дает нам больше подсказок?
$ go test -bench "BenchmarkRowBasedTypedBatch" -cpuprofile cpu.out -o row_typed_batch_bench
$ go tool pprof ./row_typed_batch_bench cpu.out
(pprof) список следующий
Итого: 990мс
ROUTINE ======================== _ ~ / scratch / vecdeepdive.mulInt64BatchOperator.next в ~ / scratch / vecdeepdive / row_based_typed_batch.go
950 мс 950 мс (плоский, диплом) 95,96% от общего
, , 15: func (m mulInt64BatchOperator) next () [] [] TypedDatum {
, , 16: строки: = m.input.next ()
, , 17: если строки == ноль {
, , 18: вернуть ноль
, , 19:}
210 мс 210 мс 20: для _, строка: = ряд строк {
300 мс 300 мс 21: для _, c: = диапазон m.columnsToMultiply {
440ms 440ms 22: строка [c] = TypedDatum {t: Int64Type, int64: строка [c] .int64 * m.arg}
, , 23:}
, , 24:}
, , 25: вернуть строки
, , 26:}
Теперь время вызова (* typedBatchTableReader) .next едва регистрируется в профиле! Это намного лучше. Профиль показывает, что строки 20-22 - это, вероятно, лучшее место, чтобы сосредоточить наши усилия дальше. Эти линии находятся там, где намного больше 95% времени. Отчасти это хороший знак, потому что эти строки реализуют основную логику нашего оператора.
Тем не менее, безусловно, есть еще возможности для совершенствования. Приблизительно половина времени, проведенного в этих трех строках, заключается только в итерациях по циклам, а не в самом теле цикла. Если мы будем думать о размерах петель, то это станет более понятным. Длина партии строк составляет 1024 но длина столбцов столбцовToMultiply [194599][19459просто 1 . Поскольку цикл row является внешним циклом, это означает, что мы настраиваем этот крошечный внутренний цикл - инициализируем счетчик, увеличиваем его и проверяем граничное условие - 1024 раз! Мы могли бы избежать всей этой повторяющейся работы, просто изменив порядок двух циклов.
Хотя мы не будем вдаваться в подробное исследование архитектуры ЦП в этом посте, при изменении порядка циклов вступают в действие две важные концепции: предсказание ветвлений и конвейеризация. Чтобы ускорить выполнение, процессоры используют технику, называемую конвейерной обработкой, чтобы начать выполнение следующей инструкции до того, как предыдущая будет завершена. Это хорошо работает в случае последовательного кода, но всякий раз, когда существуют условные переходы, ЦП не может с уверенностью определить, какой будет следующая инструкция после перехода. Тем не менее, он может сделать предположение о том, какая ветвь будет следовать. Если ЦП угадает неправильно, работа, которую ЦП уже выполнил, чтобы приступить к оценке следующей инструкции, будет потеряна. Современные процессоры способны делать прогнозы на основе статического анализа кода и даже результатов предыдущих оценок той же ветви.
Изменение порядка циклов дает еще одно преимущество. Поскольку внешний цикл теперь сообщит нам, с каким столбцом работать, мы можем загрузить все данные для этого столбца одновременно и сохранить их в памяти в одном смежном срезе. Важнейшим компонентом современной архитектуры процессора является подсистема кеша. Чтобы избежать слишком частой загрузки данных из основной памяти, что является относительно медленной операцией, ЦП имеют уровни кэшей, которые обеспечивают быстрый доступ к часто используемым частям данных, и они также могут предварительно выбирать данные в эти кэши, если схема доступа предсказуема. , В примере на основе строк мы загружали бы все данные для каждой строки, которые включали бы столбцы, на которые оператор вообще не влиял, поэтому не так много релевантных данных поместилось бы в кэш ЦП. Ориентация данных, над которыми мы будем работать, по столбцам обеспечивает центральный процессор с точно предсказуемостью и плотной упаковкой памяти, необходимой для идеального использования его кэшей.
Более подробное описание конвейерной работы, прогнозирования ветвлений и процессорных кэшей см. В заметках Дэна Луу по прогнозированию ветвлений его публикация в блоге о кэш-памяти ЦП. или Заметки Дейва Чейни из его High Performance Go Workshop .
Приведенный ниже код показывает, как мы могли бы сделать изменения ориентации цикла и данных, описанные выше, а также определить несколько новых типов одновременно, чтобы облегчить работу с кодом.
Тип векторного интерфейса {
// Тип возвращает тип данных, хранящихся в этом векторе.
Тип () T
// Int64 возвращает срез int64.
Int64 () [] int64
// Float64 возвращает фрагмент float64.
Float64 () [] float64
}
Тип colBatch struct {
размер int
вектор [] вектор
}
func (m mulInt64ColOperator) next () colBatch {
batch := m.input.next()
if batch.size == 0 {
return batch
}
for _, c := range m.columnsToMultiply {
vec := batch.vecs[c].Int64()
for i := range vec {
vec[i] = vec[i] * m.arg
}
}
return batch
}
The reason we introduced the new vector type is so that we could have one struct that could represent a batch of data of any type. The struct has a slice field for each type, but only one of these slices will ever be non-nil. You may have noticed that we have now re-introduced some interface conversion, but the performance price we pay for it is now amortized thanks to batching. Let’s take a look at the benchmark now.
$ go test -bench "BenchmarkColBasedTyped" -count 10 > tmp && benchstat tmp && rm tmp
name time/op
ColBasedTyped-12 38.2µs ±24%
This is another nearly ~3.5x improvement, and a ~20x improvement over the original row-at-a-time version! Our speed of light benchmark is still about 2x faster than this latest version, since there is overhead in reading each batch and navigating to the columns on which to operate. For the purposes of this post, we will stop our optimization efforts here, but we are always looking for ways to make our real vectorized engine faster.
Conclusion
By analyzing the profiles of our toy execution engine’s code and employing the ideas proposed in the MonetDB/x100 paper, we were able to identify performance problems and implement solutions that improved the performance of multiplying 65,536 rows by a factor of 20x. We also used code generation to write templated code that is then generated into specific implementations for each concrete type.
In CockroachDB, we incorporated all of the changes presented in this blog post into our vectorized execution engine. This resulted in improving the CPU time of our own microbenchmarks by up to 70x, and the end-to-end latency of some queries in the industry-standard TPC-H benchmark by as much as 4x. The end-to-end latency improvement we achieved is a lot smaller than the improvement achieved in our toy example, but note that we only focused on improving the in-memory execution of a query in this blog post. When running TPC-H queries on CockroachDB, data needs to be read from disk in its original row-oriented format before processing, which will account for the lion’s share of the query’s execution latency. Nevertheless, this is a great improvement.
In CockroachDB 19.2, you will be able to enjoy these performance benefits on many common scan, join and aggregation queries. Here’s a demonstration of the original sample query from this blog post, which runs nearly 2 times as fast with our new vectorized engine:
oot@127.0.0.1:64128/defaultdb> CREATE TABLE inventory (id INT PRIMARY KEY, price FLOAT);
CREATE TABLE
Time: 2.78ms
root@127.0.0.1:64128/defaultdb> INSERT INTO inventory SELECT id, random()*10 FROM generate_series(1,10000000) g(id);
INSERT 100000
Time: 521.757ms
root@127.0.0.1:64128/defaultdb> EXPLAIN SELECT count(*) FROM inventory WHERE price * 0.8 > 3;
tree | field | description
+----------------+-------------+---------------------+
| distributed | true
| vectorized | true
group | |
│ | aggregate 0 | count_rows()
│ | scalar |
└── render | |
└── scan | |
| table | inventory@primary
| spans | ALL
| filter | (price * 0.8) > 3.0
(10 rows)
Time: 3.076ms
The EXPLAIN plan for this query shows that the vectorized field is truewhich means that the query will be run with the vectorized engine by default. And, sure enough, running this query with the engine on and off shows a modest performance difference:
root@127.0.0.1:64128/defaultdb> SELECT count(*) FROM inventory WHERE price * 0.8 > 3;
подсчитывать
+---------+
6252335
(1 row)
Time: 3.587261s
root@127.0.0.1:64128/defaultdb> set vectorize=off;
SET
Time: 283µs
root@127.0.0.1:64128/defaultdb> SELECT count(*) FROM inventory WHERE price * 0.8 > 3;
подсчитывать
+---------+
6252335
(1 row)
Time: 5.847703s
In CockroachDB 19.2, the new vectorized engine is automatically enabled for supported queries that are likely to read more rows than the vectorize_row_count_threshold setting (which defaults to 1,024). Queries with buffering operators that could potentially use an unbounded amount of memory (like global sorts, hash joins, and unordered aggregations) are implemented but not yet enabled by default. For full details of what is and isn’t on by default, check out the vectorized execution engine docs. And to learn more about how we built more complicated vectorized operators check out our blog posts on the vectorized hash joiner and the vectorized merge joiner.
Please try out the vectorized engine on your queries and let us know how you fare.
Thanks for reading!







