
В наших предыдущих сообщениях в блоге мы говорили о том, как мы обновили поисковую систему Dropbox, чтобы добавить интеллект в рабочий процесс наших пользователей и как мы построили конвейер оптического распознавания символов (OCR). Одним из наиболее впечатляющих преимуществ, которые пользователи смогут увидеть из этих изменений, является то, что пользователи на Dropbox Professional и Dropbox Business Advanced и Enterprise планы могут искать текст на английском языке в изображениях и PDF-файлах, используя систему, которую мы описываем как автоматическое распознавание текста.
Потенциальное преимущество автоматического распознавания текста в изображениях (включая PDF-файлы, содержащие изображения) является огромным. В Dropbox люди хранили более 20 миллиардов изображений и файлов PDF. Из этих файлов 10-20% — это фотографии документов, подобных квитанциям и изображениям на доске, в отличие от самих документов. Теперь они являются кандидатами на автоматическое распознавание текста. Аналогичным образом, 25% этих PDF-файлов — это сканирование документов, которые также являются кандидатами на автоматическое распознавание текста.
С точки зрения компьютерного зрения, хотя документ и изображение документа может показаться очень похожим на человека, есть большая разница в том, как компьютеры видят эти файлы: документ может быть индексирован для поиска, что позволяет пользователям находить его, введя несколько слов из файла; изображение непрозрачно для поиска систем индексирования, поскольку оно отображается только как совокупность пикселей. Форматы изображений (например, JPEG, PNG или GIF) обычно не индексируются, потому что они не имеют текстового содержимого, а текстовые форматы документов (например, TXT, DOCX или HTML) обычно индексируются. Файлы PDF попадают между ними, потому что они могут содержать смесь текста и содержимого изображения. Автоматическое распознавание текста изображения позволяет разумно различать все эти документы для категоризации данных, содержащихся внутри.
![]()
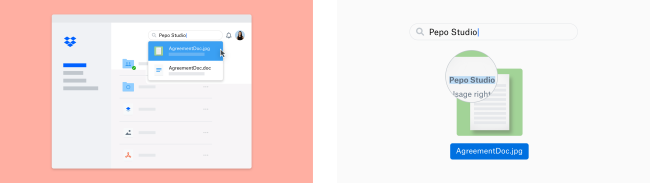
Итак, теперь, когда пользователь ищет текст на английском языке, который появляется в одном из этих файлов, он будет отображаться в результатах поиска. Это сообщение в блоге описывает, как мы построили эту функцию.
Содержание статьи
Оценка проблемы
Во-первых, мы решили оценить размер задачи, в частности, попытаться понять объем данных, которые нам пришлось бы обрабатывать. Это не только сообщит о сметной стоимости, но и подтвердит ее полезность. В частности, мы хотели ответить на следующие вопросы:
- Какие типы файлов мы должны обрабатывать?
- Какой из этих файлов может иметь контент, доступный для OCR?
- Для многостраничных типов документов, таких как PDF-файлы, сколько страниц нужно обработать, чтобы сделать это полезным?
Типы файлов, которые мы хотим обработать, это те, которые в настоящее время не имеют индексного текстового содержимого. Сюда входят форматы изображений и файлы PDF без текстовых данных. Однако не все изображения или файлы PDF содержат текст; на самом деле, большинство из них — это просто фотографии или иллюстрации без текста. Таким образом, ключевым строительным блоком была модель машинного обучения, которая могла бы определить, был ли данный фрагмент контента доступным для OCR, другими словами, имеет ли он текст, который имеет хороший шанс быть узнаваемым нашей системой OCR. Это включает, например, сканирование или фотографии документов, но исключает такие вещи, как изображения со случайным знаком улицы. Модель, которую мы обучали, была сверточной нейронной сетью, которая принимает входное изображение перед преобразованием своего вывода в двоичное решение о том, может ли он иметь текстовое содержимое.
Для изображений наиболее распространенным типом изображения является JPEG, и мы обнаружили, что примерно 9% JPEG могут содержать текст. Для PDF-файлов ситуация немного сложнее, так как PDF может содержать несколько страниц, и каждая страница может существовать в одной из трех категорий:
- Страница имеет текст, который уже встроен и индексируется
- Страница имеет текст, но только в виде изображения и, следовательно, в настоящее время не индексируется
- Страница не содержит существенного текстового контента
Мы хотели бы пропустить страницы в категориях 1 и 3 и сосредоточиться только на категории 2, поскольку именно здесь мы можем обеспечить преимущество. Оказывается, распределение страниц в каждом из трех ведер составляет 69%, 28% и 3% соответственно. В целом, наши целевые пользователи имеют примерно в два раза больше JPEG, чем PDF-файлы, но каждый PDF имеет в среднем 8,8 страниц, а в файлах PDF гораздо более высокая вероятность содержать текстовые изображения, поэтому с точки зрения общей нагрузки на нашу систему, PDF-файлы будут способствовать более 10-кратным как JPEG! Однако оказывается, что мы могли бы значительно уменьшить это число за счет простого анализа, описанного ниже.
Общее количество страниц
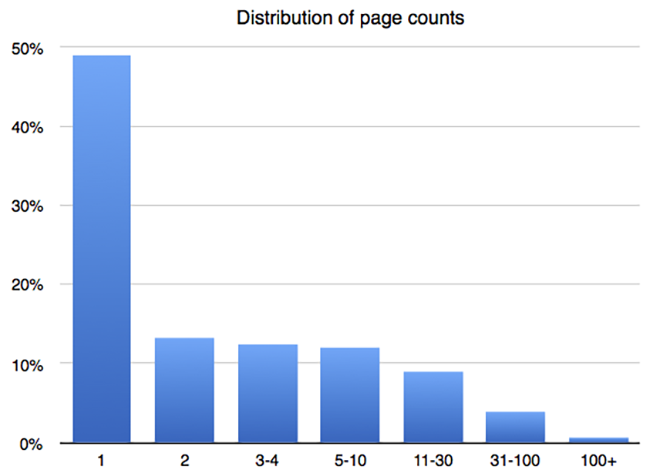
Как только мы определили типы файлов и разработали оценку того, сколько контента, доступных для OCR, проживало на каждой странице, мы хотели быть стратегическими относительно того, как мы подошли к каждому файлу. В некоторых документах PDF есть много страниц, поэтому обработка этих файлов является более дорогостоящей. К счастью, для длинных документов мы можем воспользоваться тем фактом, что даже индексирование нескольких страниц, скорее всего, сделает документ более доступным для поиска. Таким образом, мы рассмотрели распределение количества страниц по выборке PDF-файлов, чтобы выяснить, сколько страниц мы будем индексировать максимум для каждого файла. Оказывается, что половина PDF-файлов имеет только 1 страницу, а примерно 90% имеют 10 страниц или меньше. Итак, мы пошли с кепкой в 10 страниц — первые 10 в каждом документе. Это означает, что мы полностью индексируем почти 90% документов, и мы индексируем достаточное количество оставшихся документов, чтобы сделать их доступными для поиска.
![]()
Предоставление
Как только мы начали процесс извлечения текста с помощью OCR во всех файлах, доступных для OCR, мы поняли, что у нас есть две возможности для рендеринга данных изображения, встроенных в файлы PDF: мы могли бы извлечь все растровые (т.е. пиксельные) объекты изображения, встроенные в файловом потоке отдельно, или мы могли бы отображать все страницы PDF для растровых данных изображения. После экспериментов с обоими мы выбрали последнее, потому что у нас уже была мощная крупномасштабная инфраструктура рендеринга PDF для нашей функции предварительного просмотра файлов. Некоторые преимущества использования этой системы включают в себя:
- Он может быть естественно распространен на другие форматы файлов изображений или изображений, таких как PowerPoint, PostScript и многие другие форматы, поддерживаемые нашей инфраструктурой предварительного просмотра
- Фактический рендеринг естественным образом сохраняет порядок текстовых токенов и положение текста в макете, принимая во внимание структуру документа, что не гарантируется при извлечении отдельных изображений из макета с несколькими изображениями
Реализацию на стороне сервера, используемую в нашей инфраструктуре предварительного просмотра, основаны на PDFium, рендерере PDF в проекте Chromium, проекте с открытым исходным кодом, запущенном Google, который является основой браузера Chrome. Это же программное обеспечение также используется для обнаружения текстового текста и для определения того, является ли документ «только для изображений», что помогает решить, хотим ли мы применять обработку OCR.
Как только мы начинаем рендеринг, страницы каждого документа обрабатываются параллельно для более низкой латентности, ограниченные на первых 10 страницах на основе нашего анализа выше. Мы отображаем каждую страницу с разрешением, которое заполняет прямоугольник 2048 на 2048 пикселей, сохраняя соотношение сторон.
Классификация изображений документов
Наша модель машинного обучения, основанная на OCR, была первоначально построена для функции сканера документов Dropbox, чтобы выяснить, были ли пользователи недавно (обычные) фотографии, которые мы могли бы предложить, чтобы они «превратились в сканирование». Этот классификатор был построен с использованием линейный классификатор поверх функций изображения из предварительно подготовленной модели ImageNet (GoogLeNet / Inception). Он был подготовлен на нескольких тысячах изображений, собранных из нескольких разных источников, включая общедоступные изображения, изображения, пожертвованные пользователями, и некоторые пожертвованные изображения Dropbox-работника. Первоначальная версия разработки была построена с использованием Caffe, и модель позже была преобразована в TensorFlow для согласования с другими нашими развертываниями.
При тонкой настройке производительности этого компонента мы выучили важный урок: в начале классификатор иногда создавал ложные срабатывания (изображения, которые, по его мнению, содержали текст, но на самом деле этого не делал), например, изображения пустых стен, или открытая вода. Хотя они кажутся совершенно разными для человеческих глаз, классификатор увидел что-то очень похожее во всех этих изображениях: все они имели гладкие фоны и горизонтальные линии. Итеративно маркируя и добавляя так называемые «жесткие негативы» к набору тренировок, мы значительно улучшили точность классификации, эффективно обучая классификатор, что хотя эти изображения имели многие характеристики текстовых документов, они не содержали фактических текст.
Угловое обнаружение
Расположение углов документа на изображении и определение его (приблизительно) четырехугольной формы — еще один ключевой шаг перед распознаванием символов. Учитывая координаты углов, документ в изображении может быть исправлен (сделан в прямоугольный прямоугольник) с простым геометрическим преобразованием. Компонент углового детектора документа был построен с использованием другой глубокой сверточной сети ImageNet (Densenet-121), а его верхний слой заменен регрессором, который производит квадратные угловые координаты.
В тестовых данных для обучения этой модели использовалось всего несколько сотен изображений. Этикетки в виде четырех или более двухмерных точек, которые определяют замкнутый многогранник документа, также были нарисованы рабочими-механиками Turk с использованием пользовательского пользовательского интерфейса, дополненного аннотациями членов команды Machine Learning. Часто один или несколько углов документа, содержащегося в учебных изображениях, находятся за пределами границ изображения, что требует некоторой человеческой интуиции для заполнения недостающих данных.
Поскольку глубокая сверточная сеть питается уменьшенными изображениями, необработанное предсказанное местоположение четырехугольника имеет меньшее разрешение, чем исходное изображение. Чтобы повысить точность, мы применяем двухэтапный процесс:
- Получить начальный квад
- Запустите еще одну регрессию на патче с высоким разрешением вокруг каждого угла
Из координат квадрата, тогда легко исправить изображение в выровненную версию.
Добыча маркера
Фактическая система распознавания оптических символов, которая извлекает текстовые токены (примерно соответствующие словам), описана в нашем предыдущем сообщении в блоге. Он берет исправленные изображения с этапа обнаружения угла в качестве входных данных и генерирует обнаружение токенов, которые включают ограничивающие поля для токенов и текст каждого токена. Они упорядочены в последовательный список токенов и добавляются в индекс поиска. Если есть несколько страниц, списки токенов на каждой странице объединяются вместе, чтобы сделать один большой список.
Сложение частей
![]()
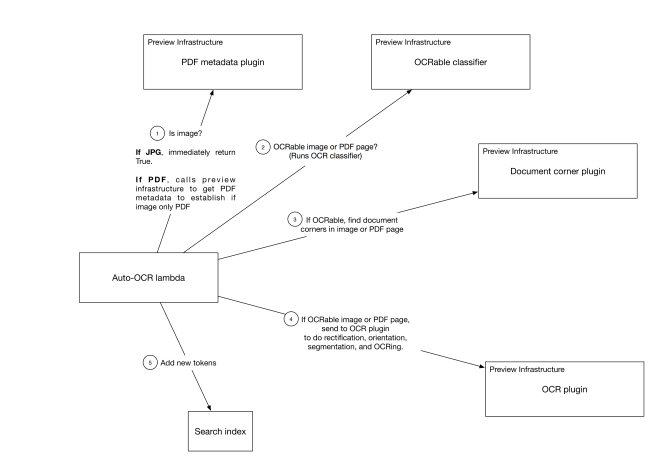
Чтобы запустить автоматическое распознавание текста во всех файлах с возможностью индексирования для всех подходящих пользователей, нам нужна система, которая может поглощать входящие события файла (например, добавлять или редактировать) и запускать соответствующую обработку. Это оказывается естественным прецедентом для Cape, гибкой, крупномасштабной, с малой задержкой, для асинхронной обработки потока событий, которая задействует многие функции Dropbox. Мы добавили нового работника по обслуживанию микроавтобусов в Кейп (называемого «лямбда») для обработки OCR в рамках общей структуры индексирования поиска.
Первые несколько шагов обработки используют преимущества общей инфраструктуры предварительного просмотра Dropbox. Это система, которая может эффективно принимать двоичный файл в качестве входных данных и возвращать преобразование этого файла. Например, он может взять файл PowerPoint и создать уменьшенное изображение этого файла PowerPoint. Система расширяема через плагины, которые работают с определенными типами файлов и возвращают определенные преобразования; таким образом, добавить новый тип файла или преобразование легко. Наконец, система также эффективно кэширует преобразования, так что, если мы попытаемся сгенерировать эскиз одного файла PowerPoint дважды, дорогостоящая операция миниатюр будет выполняться только один раз.
Мы написали несколько предварительных плагинов для этой функции, включая (номера соответствуют системной диаграмме выше):
- Проверьте, следует ли нам продолжать обработку на основе того, является ли это JPEG, GIF, TIFF или PDF без встроенного текста, и если пользователь имеет право на эту функцию
- Запустите OCR-способный классификатор, который определяет, имеет ли данное изображение текст
- Запустите детектор угла документа на каждом изображении, чтобы мы могли его исправить
- Извлечь жетоны с помощью двигателя OCR
- Добавить список токенов в индекс поиска пользователя
Робастность
Чтобы повысить надежность системы в случае временных / временных ошибок во время удаленных вызовов, мы повторяем удаленные вызовы с использованием экспоненциального отклика с помощью джиттера, наилучшей практики в распределенных системах. Например, мы достигли 88% -ного снижения частоты отказов для извлечения метаданных PDF, повторив второй и третий раз.
Оптимизация производительности
Когда мы развернули исходную версию конвейера на долю трафика для тестирования, мы обнаружили, что вычислительные издержки наших моделей машинного обучения (обнаружение углов, определение ориентации, OCRing и т. Д.) Потребуют огромного кластера, который сделать эту функцию слишком дорогостоящей для развертывания. Кроме того, мы обнаружили, что объем трафика, который мы наблюдали за потоком, составлял примерно 2, что мы оценили, он должен основываться на исторических темпах роста.
Чтобы решить эту проблему, мы начали с улучшения пропускной способности наших моделей обучения машинам OCR с предположением, что увеличение пропускной способности обеспечило максимальный эффект сокращения размера кластера OCR, который нам понадобится.
Для точного контролируемого бенчмаркинга мы создали выделенную изолированную среду и инструменты командной строки, которые позволили нам отправлять входные данные нескольким вспомогательным службам для измерения пропускной способности и латентности каждого из них по отдельности. Журналы секундомера, которые мы использовали для бенчмаркинга, были отобраны из фактического прямого трафика без остаточного сбора данных.
Мы решили подойти к оптимизации производительности извне, начиная с параметров конфигурации. Когда вы сталкиваетесь с узкими местами, связанными с машинным обучением, большие достижения производительности иногда могут быть достигнуты благодаря простой настройке и изменениям в библиотеке; мы обсудим несколько примеров ниже.
Первое повышение произошло от выбора правильной степени параллелизма для кода, запущенного в тюрьмах: для обеспечения безопасности мы запускаем самый код, который напрямую касается содержимого пользователя в программной тюрьме, который ограничивает выполнение каких-либо операций, изолирует контент от разных пользователей до предотвратить ошибки программного обеспечения от развращения данных и защитить нашу инфраструктуру от вредоносных векторов угроз. Обычно мы развертываем одну тюрьму на ядро на машине, чтобы обеспечить максимальный параллелизм, позволяя каждой тюрьме запускать только однопоточный код (т. Е. Параллелизм данных).
Однако оказалось, что система глубокого обучения TensorFlow, которую мы используем для прогнозирования символов из пикселей, по умолчанию поддерживает многоядерную поддержку. Это означало, что в каждой тюрьме теперь был запущен многопоточный код, что привело к огромному объему накладных расходов на переключение контекста. Поэтому, выключив многоядерную поддержку в TensorFlow, мы смогли увеличить пропускную способность примерно на 3 раза.
После этого исправления мы обнаружили, что производительность была все еще слишком медленной — запросы становились узкими, даже до того, как мы поразили наши модели машинного обучения! После того, как мы настроили количество предварительно выделенных тюрем и экземпляров сервера RPC для количества ядер процессора, которые мы использовали, мы, наконец, начали получать ожидаемую пропускную способность. Мы получили дополнительный значительный импульс, предоставив векторизованные инструкции AVX2 в TensorFlow и предварительно скомпилировав модель и среду выполнения в библиотеку C ++ через TensorFlow XLA. Наконец, мы сравнили модель с тем, что 2D свертки на узких промежуточных слоях были горячими точками и ускорили их вручную, развернув их на графике.
Два важных компонента конвейера изображения документа — это определение угла и прогнозирование ориентации, которые реализованы с использованием глубоких сверточных нейронных сетей. По сравнению с моделью Inception-Resnet-v2, которую мы использовали раньше, мы обнаружили, что Densenet-121 был почти в два раза быстрее и лишь немного менее точным в прогнозировании местоположения углов документа. Чтобы удостовериться, что мы не слишком сильно регрессировали, мы провели тест A / B для оценки практического воздействия на удобство использования, сравнивая, как часто пользователи вручную исправляли автоматически предсказанные углы документа. Мы пришли к выводу, что разница была незначительной, и увеличение производительности было оправдано.
Прокладывает путь для будущих умных функций
Создание изображений изображений, доступных для поиска, является первым шагом на пути к более глубокому пониманию структуры и содержания документов. С помощью этой информации Dropbox может помочь пользователям лучше организовать свои файлы — шаг на пути к более просвещенному способу работы.
Автоматическое распознавание текста изображений является ярким примером типа крупномасштабных проектов, связанных с компьютерным зрением и машинным обучением, которые инженеры в решении Dropbox. Если вас интересуют эти проблемы, мы бы хотели, чтобы вы были в нашей команде.
Спасибо: Алан Шие, Брэд Нойберг, Дэвид Кригман, Чонмин Бэк, Леонард Финк, Питер Белхумеур.







