


Я знаю, что вы думаете. Вот еще одна статья о сокращении зависимостей JavaScript и размере пакета, отправляемого клиенту. Но эта немного другая, я обещаю.
Эта статья посвящена паре вещей, с которыми столкнулась Bookaway, и нам (как компании, работающей в сфере путешествий) удалось оптимизировать наши страницы, так что HTML мы отправить меньше. Меньший размер HTML означает, что у Google меньше времени для загрузки и обработки этих длинных строк текста.
Обычно размер кода HTML не является большой проблемой, особенно для небольших страниц, не требующих большого объема данных, или страниц, которые не являются SEO-ориентированный. Однако на наших страницах дело обстояло иначе, поскольку наша база данных хранит много данных, и нам нужно обслуживать тысячи целевых страниц в масштабе.
Вам может быть интересно, зачем нам такой масштаб. Что ж, Bookaway работает с 1500 операторами и предоставляет более 20 тыс. Услуг в 63 странах с ростом на 200% в год (до Covid-19). В 2019 году мы продавали 500 тыс. Билетов в год, поэтому наши операции сложны, и нам нужно продемонстрировать это на наших целевых страницах привлекательно и быстро. Как для роботов Google (SEO), так и для реальных клиентов.
В этой статье я объясню:
- как мы обнаружили, что размер HTML слишком велик;
- как это было сокращено;
- преимущества этого процесса (например, создание улучшенной архитектуры, улучшение организации одежды, предоставление Google простой работы по индексированию десятков тысяч целевых страниц и предоставление гораздо меньшего количества байтов для клиент — особенно подходит для людей с медленным подключением).
Но сначала давайте поговорим о важности повышения скорости.
Почему повышение скорости необходимо для наших усилий по поисковой оптимизации?
Познакомьтесь с «Web Vitals», но, в частности, с LCP (Крупнейшая Contentful Paint):
«Крупнейшая Contentful Paint (LCP) — важный, ориентированный на пользователя показатель для измерения воспринимаемой скорости загрузки, потому что он отмечает момент на шкале времени загрузки страницы, когда основное содержимое страницы, вероятно, загружено — fa st LCP помогает убедить пользователя в том, что страница полезна ».
Основная цель — иметь по возможности небольшую LCP. Частично наличие небольшой LCP позволяет пользователю загружать как можно меньший HTML-код. Таким образом, пользователь может как можно скорее начать процесс рисования самой крупной раскраски контента.
Хотя LCP — это показатель, ориентированный на пользователя, его уменьшение должно сильно помочь ботам Google, как утверждает Googe:
«Интернет — это почти бесконечное пространство, превосходящее возможности Google по изучению и индексации всех доступных URL. В результате существуют ограничения на то, сколько времени робот Googlebot может тратить на сканирование любого отдельного сайта. Количество времени и ресурсов, затрачиваемых Google на сканирование сайта, обычно называется бюджетом сканирования сайта ».
-« Advanced SEO », Документация центра поиска Google
Один из лучших технических способов улучшить бюджет сканирования призван помочь Google сделать больше за меньшее время:
Q : «Влияет ли скорость сайта на мой бюджет сканирования? Как насчет ошибок? »
A :« Ускорение сайта улучшает работу пользователей, а также увеличивает скорость сканирования. Для Googlebot быстрый сайт является признаком исправных серверов, так что он может получать больше контента при том же количестве подключений ».
Подводя итог, боты Google и клиенты Bookaway преследуют одну и ту же цель. — они оба хотят, чтобы контент доставлялся быстро. Поскольку наша база данных содержит большой объем данных для каждой страницы, нам необходимо эффективно их агрегировать и отправлять клиентам что-то маленькое и тонкое.
Исследования способов улучшения привели к обнаружению большого размера JSON. встроены в наш HTML, что делает HTML коренастым. В этом случае нам нужно понять React Hydration.
React Hydration: Почему в HTML есть JSON
Это происходит из-за того, как рендеринг на стороне сервера работает в react и Next. js:
- Когда запрос поступает на сервер, он должен создать HTML на основе сбора данных. Этот набор данных является объектом, возвращаемым
getServerSideProps. - React получил данные. Теперь он вступает в игру на сервере. Он встраивает HTML и отправляет его.
- Когда клиент получает HTML, он сразу же испытывает боль перед ним. Тем временем React javascript загружается и выполняется.
- Когда выполнение javascript завершено, React снова включается в игру, теперь уже на клиенте. Он снова строит HTML и присоединяет слушателей событий. Это действие называется гидратацией.
- Поскольку React снова строит HTML для процесса гидратации, он требует того же сбора данных, что и на сервере (посмотрите
1.). - Этот сбор данных становится доступным путем вставки JSON в тег скрипта с идентификатором
__ NEXT_DATA __.
О каких страницах мы говорим именно?
Поскольку нам необходимо продвигать наши предложения в поисковых системах, возникла потребность в целевых страницах. Обычно люди не ищут название конкретной автобусной линии, а скорее спрашивают: «Как добраться из Бангкока в Паттайю?» На данный момент мы создали четыре типа целевых страниц, которые должны отвечать на такие запросы:
- Город A в город B
Все линии проходят от станции в городе A до станции в городе Б. (например, из Бангкока в Паттайю) - Город
Все линии, проходящие через определенный город. (например, Канкун) - Страна
Все линии, которые проходят через определенную страну. (например, Италия) - Станция
Все линии, которые проходят через определенную станцию. (например, аэропорт Ханоя)
Теперь взглянем на архитектуру
Давайте взглянем на высокоуровневый и очень упрощенный взгляд на инфраструктуру, обеспечивающую работу целевых страниц, о которых мы говорим. Интересные части находятся на 4 и 5 . Вот где бесполезные детали:
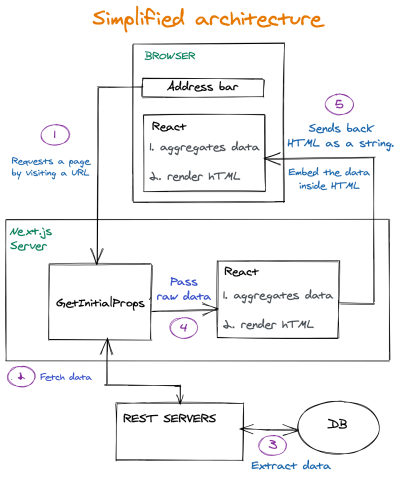
Ключевые выводы из процесса
- Запрос попадает в функцию
getInitialProps. Эта функция работает на сервере. Эта функция отвечает за получение данных, необходимых для создания страницы. - Необработанные данные, возвращаемые с серверов REST, передаются в React как есть.
- Во-первых, они выполняются на сервере. Поскольку неагрегированные данные были переданы в React, React также отвечает за агрегацию данных во что-то, что может использоваться компонентами пользовательского интерфейса (подробнее об этом в следующих разделах)
- HTML отправляется в client вместе с необработанными данными. Затем React снова вступает в игру также в клиенте и выполняет ту же работу. Потому что необходима гидратация (подробнее об этом в следующих разделах). Итак, React выполняет агрегирование данных дважды.
Проблема
Анализ процесса создания нашей страницы привел нас к обнаружению большого JSON, встроенного в HTML. Точно сказать сложно. Каждая страница немного отличается, потому что каждая станция или город должны агрегировать разные наборы данных. Однако можно с уверенностью сказать, что размер JSON на популярных страницах может достигать 250 КБ. Позже он был уменьшен до размеров 5-15 КБ. Значительное сокращение. На некоторых страницах висело около 200-300 кб. Это большой .
Большой JSON встроен в тег скрипта с идентификатором ___ NEXT_DATA ___ :
Если вы хотите легко скопировать этот JSON в буфер обмена, попробуйте этот фрагмент на своей странице Next.js:
copy ($ ('#__ NEXT_DATA__'). innerHTML)
Возникает вопрос:
Почему он такой большой? Что там?
Отличный инструмент, анализатор размера JSON, знает, как обрабатывать JSON, и показывает, где находится большая часть размера.
Это были наши первые выводы при исследовании станции страница:
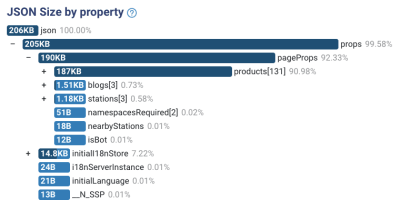
Там есть две проблемы с анализом:
- Данные не агрегированы.
Наш HTML содержит полный список отдельных продуктов. Они нам не нужны для рисования на экране. Они нам действительно нужны для методов агрегирования. Например, мы получаем список всех линий, проходящих через эту станцию. У каждой линии есть поставщик. Но нам нужно сократить список строк до массива из 2-х поставщиков. Это оно. Позже мы увидим пример. - Ненужные поля.
При сверлении каждого объекта мы увидели некоторые поля, которые нам совсем не нужны. Не для агрегирования и не для окраски. Это потому, что мы получаем данные из REST API. Мы не можем контролировать, какие данные мы получаем.
Эти две проблемы показали, что страницы нуждаются в изменении архитектуры. Но ждать. Зачем вообще нам нужен JSON с данными, встроенный в наш HTML? 🤔
Изменение архитектуры
Проблема очень большого JSON должна быть решена в аккуратном и многоуровневом решении. Как? Хорошо, добавив слои, отмеченные зеленым на следующей диаграмме:
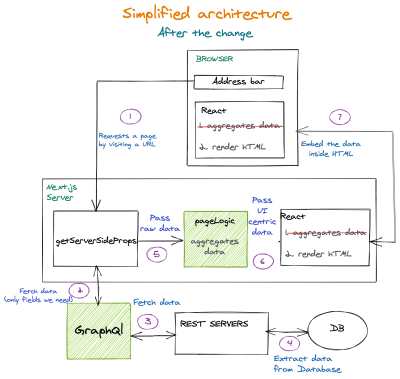
Несколько замечаний:
- Двойное агрегирование данных было удалено и объединено, и теперь оно выполняется только один раз только на сервере Next.js;
- Добавлен уровень сервера Graphql. Это гарантирует, что мы получим только те поля, которые нам нужны. База данных может увеличиваться с большим количеством полей для каждой сущности, но это нас больше не повлияет; функция
-
PageLogicдобавлена вgetServerSideProps. Эта функция получает неагрегированные данные от серверных служб. Эта функция агрегирует и подготавливает данные для компонентов пользовательского интерфейса. (Он работает только на сервере.)
Пример потока данных
Мы хотим отобразить этот раздел со страницы станции:
Нам нужно знать, кто поставщики работают на данной станции. Нам нужно получить все строки для конечной точки строк REST. Вот что мы получили ответ (например, цель, на самом деле она была намного больше):
[
{
id: "58a8bd82b4869b00063b22d2",
class: "Standard",
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
id: "58f5e40da02e97f000888e07a",
class: "Luxury",
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
id: "58f5e4a0a02e97f000325e3a",
class: 'Luxury',
supplier: "Jones Ltd",
type: "minivan",
},
];
[
{ supplier: "Hyatt-Mosciski", amountOfLines: 2, types: ["bus"]},
{поставщик: "Jones Ltd", amountOfLines: 1, types: ["minivan"]},
];
Как видите, у нас есть несколько нерелевантных полей. картинки и id не будут играть никакой роли в разделе. Поэтому мы вызовем Graphql Server и запросим только те поля, которые нам нужны. Теперь это выглядит так:
[
{
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
supplier: "Hyatt-Mosciski",
type: "bus",
},
{
supplier: "Jones Ltd",
type: "minivan",
},
];
Теперь с этим объектом легче работать. Он меньше по размеру, легче поддается отладке и занимает меньше памяти на сервере. Но это еще не агрегирование. Это не та структура данных, которая требуется для фактического рендеринга.
Давайте отправим ее в функцию PageLogic чтобы обработать ее и посмотреть, что мы получим:
[
{ supplier: "Hyatt-Mosciski", amountOfLines: 2, types: ["bus"]},
{поставщик: "Jones Ltd", amountOfLines: 1, types: ["minivan"]},
];
Этот небольшой набор данных отправляется на страницу Next.js.
Теперь он готов для рендеринга пользовательского интерфейса. Больше не нужно хрустеть и готовиться. Кроме того, теперь он очень компактен по сравнению с исходной коллекцией данных, которую мы извлекли. Это важно, потому что таким образом мы будем отправлять клиенту очень мало данных.
Как измерить влияние изменений
Уменьшение размера HTML означает, что нужно загружать меньше битов. Когда пользователь запрашивает страницу, она получает полностью сформированный HTML за меньшее время. Это можно измерить в загрузке контента ресурса HTML на сетевой панели.
Выводы
Доставка тонких ресурсов имеет важное значение, особенно когда дело касается HTML. Если HTML становится большим, у нас нет места для ресурсов CSS или javascript в нашем бюджете производительности.
Лучше всего предполагать, что многие реальные пользователи будут использовать не iPhone 12, а скорее устройство среднего уровня в сети среднего уровня. Оказывается, что уровни производительности довольно жесткие, о чем говорится в популярной статье:
«Благодаря прогрессу в сетях и браузерах (но не в устройствах), для сайтов, созданных «современный» способ. Теперь мы можем позволить себе ~ 100 КБ HTML / CSS / шрифтов и ~ 300–350 КБ JS (в сжатом виде). Это практическое ограничение должно сохраняться как минимум год или два. Как всегда, дьявол в сносках, но верхняя строчка осталась неизменной: когда мы конструируем цифровой мир до пределов лучших устройств, мы строим менее пригодный для использования более 80% пользователей мира »
Влияние на производительность
Мы измеряем влияние на производительность по времени, которое требуется для загрузки HTML при медленном регулировании скорости 3G. эта метрика называется «загрузка контента» в Chrome Dev Tools.
Вот пример метрики для страницы станции:
| Размер HTML (до gzip) | Время загрузки HTML (медленное 3G) | |
|---|---|---|
| До | 370kb | 820 мс |
| После | 166 | 540 мс |
| Общее изменение | Уменьшение на 204 КБ | 34% Снижение |
Многослойное решение
Изменения архитектуры включали дополнительные уровни:
- Сервер GraphQl : помощники с получением именно того, что мы хотим.
- Выделенная функция для агрегирования : работает только на сервере.
Изменены, кроме чистого выступление Усовершенствования, а также предлагали гораздо лучшую организацию кода и возможности отладки:
- Вся логика, касающаяся сокращения и агрегирования данных, теперь централизована в одной функции;
- Функции пользовательского интерфейса теперь намного больше простой. Без агрегации, без обработки данных. Они просто получают данные и рисуют их;
- Отладка серверного кода более приятна, поскольку мы извлекаем только те данные, которые нам нужны — больше никаких ненужных полей, поступающих из конечной точки REST.
 (vf, il)
(vf, il) 






