
Фотографии являются одними из самых распространенных типов файлов в Dropbox, но их поиск по имени файла еще менее продуктивен, чем для текстовых файлов. Когда вы ищете фотографию с пикника несколько лет назад, вы наверняка не помните, что имя файла, установленное вашей камерой, было 2017-07-04 12.37.54.jpg .
Вместо этого вы смотрите на отдельные фотографии или их миниатюры и пытаетесь определить объекты или аспекты, которые соответствуют тому, что вы ищете — будь то восстановление сохраненной фотографии или, возможно, поиск идеального снимка для новая кампания в архивах вашей компании. Разве не было бы замечательно, если бы Dropbox мог вместо этого просматривать все эти изображения и вызывать те, которые лучше всего соответствуют нескольким описательным словам, которые вы продиктовали? Именно этим и занимается наш поиск изображений.
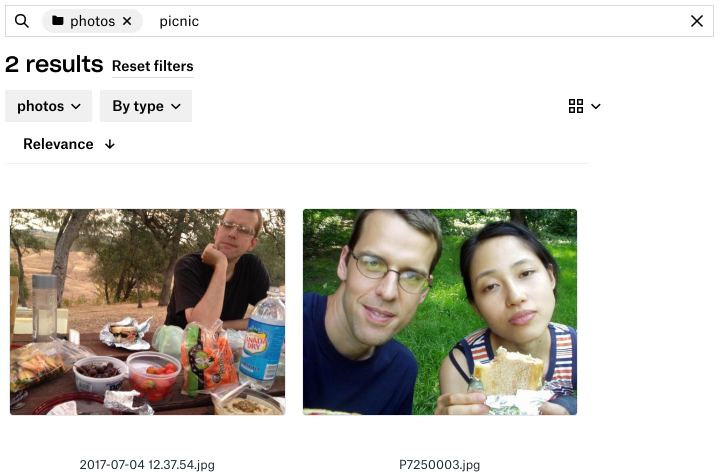
Результаты поиска изображений по запросу «пикник»
В этом посте мы опишем основную идею нашего метода поиска графического контента, основанного на методах машинного обучения, а затем обсудим, как мы создали эффективную реализацию существующей поисковой инфраструктуры Dropbox.
Вот простой способ сформулировать проблему поиска изображений: найти функцию релевантности которая принимает (текстовый) запрос q и изображение j и возвращает оценку релевантности s показывающую, насколько хорошо изображение соответствует запросу.
s = f (q, j)
При использовании этой функции, когда пользователь выполняет поиск, мы запускаем его на всех его изображениях и возвращаем те, которые дают оценку выше порогового значения, отсортированные по их оценкам. Мы создаем эту функцию, используя два ключевых достижения в области машинного обучения: точную классификацию изображений и векторы слов .
Классификация изображений
Классификатор изображений считывает изображение и выводит оцененный список категорий, описывающих его содержание. Более высокие баллы указывают на более высокую вероятность того, что изображение принадлежит этой категории.
Категории могут быть:
- конкретные объекты на изображении, например дерево или человек
- общие описания сцены, такие как на открытом воздухе или свадьба
- характеристики самого изображения, такие как черно-белое или крупный план
За последнее десятилетие был отмечен огромный прогресс в классификации изображений с использованием сверточных нейронных сетей, начиная с прорывного результата Крижевского и др. по проблеме ImageNet в 2012 году. С тех пор, с улучшением архитектуры модели , улучшенные методы обучения, большие наборы данных, такие как Open Images или ImageNet, и простые в использовании библиотеки, такие как TensorFlow и PyTorch, исследователи создали классификаторы изображений, которые могут распознавать тысячи категорий.
Посмотрите, насколько хорошо сегодня работает классификация изображений:
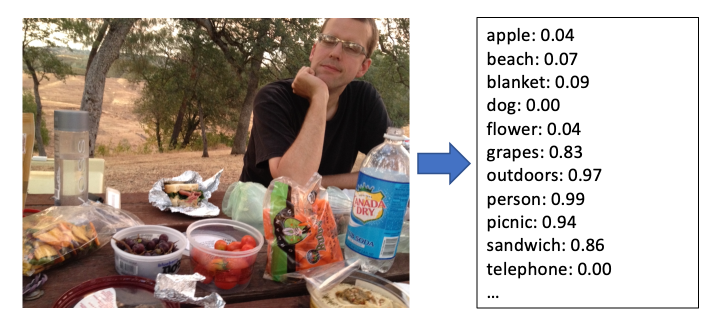
Выводы классификатора изображений для типичной неустановленной фотографии
Классификация изображений позволяет нам автоматически понимать, что на них изображено, но одного этого недостаточно для поиска. Конечно, если пользователь будет искать пляж мы сможем вернуть изображения с наивысшими оценками для этой категории, но что, если они вместо этого будут искать берег ? Что, если вместо яблока они будут искать фрукт или бабушка Смит ?
Мы могли бы сопоставить большой словарь синонимов и почти синонимов и иерархических отношений между словами, но это быстро становится громоздким, особенно если мы поддерживаем несколько языков.
Векторы слов
Итак, давайте перефразируем проблему. Мы можем интерпретировать выходные данные классификатора изображений как вектор j c оценок по категориям. Этот вектор представляет содержание изображения в виде точки в C -мерном пространстве категорий, где C — количество категорий (несколько тысяч). Если мы сможем извлечь осмысленное представление запроса в этом пространстве, мы сможем интерпретировать, насколько близок вектор изображения к вектору запроса, как меру того, насколько хорошо изображение соответствует запросу.
К счастью, выделение векторных представлений текста находится в центре внимания большого количества исследований в области обработки естественного языка. Один из наиболее известных методов в этой области описан в статье Word2vec Миколова и др. 2013 года. Word2vec назначает вектор каждому слову в словаре, так что слова с одинаковым значением будут иметь векторы, близкие друг к другу. Эти векторы находятся в d -мерном векторном пространстве слов, где d обычно составляет несколько сотен.
Мы можем получить векторное представление поискового запроса, просто просмотрев его вектор word2vec. Этот вектор не находится в пространстве категорий векторов классификатора изображений, но мы можем преобразовать его в пространство категорий, указав имена категорий изображений следующим образом:
- Для слова запроса q получите d -мерный вектор слов q w нормализованный до единичного вектора . Мы будем использовать индекс w для векторов в пространстве слов и индекс c для векторов в пространстве категорий.
- Для каждой категории получите нормализованный вектор слов для названия категории c i w . Затем определите m̂ i = q w · c i w косинус сходство между вектором запроса и вектором i -й категории. Эта оценка от -1 до 1 показывает, насколько хорошо слово запроса соответствует названию категории. Обрезав отрицательные значения до нуля, так что m i = max (0, m̂ i ), мы получим оценку в тот же диапазон, что и выходные данные классификатора изображений.
- Это позволяет нам вычислить q c = [ m 1 m 2 … m C ]вектор в C -мерном пространстве категорий, который показывает, насколько хорошо запрос соответствует каждой категории, так же как вектор классификатора изображений для каждого изображения показывает, насколько хорошо изображение соответствует каждой категории. .
Шаг 3 — это просто векторно-матричное умножение, q c = q w C где ] C — это матрица, столбцы которой являются векторами слов категорий c i w .
После того, как мы сопоставили запрос с вектором пространства категорий q c мы можем взять его косинусное сходство с вектором пространства категорий для каждого изображения, чтобы получить окончательную оценку релевантности для изображение, s = q c j c .
Это наша функция релевантности, и мы ранжируем изображения по этому баллу, чтобы показать результаты запроса. Применение этой функции к набору изображений также может быть выражено как вектор-матричное умножение, s = q c J где каждый столбец ] J — выходной вектор классификатора j c для изображения, а s — вектор оценок релевантности для всех изображений.
Давайте рассмотрим пример с несколькими измерениями, где векторы слов имеют только три измерения, а классификатор имеет только четыре категории: яблоко пляж одеяло и собака .
Предположим, пользователь искал берег. Мы ищем вектор слов, чтобы получить [0.35 -0.62 0.70]затем умножаем его на матрицу векторов слов категорий, чтобы спроецировать запрос в пространство категорий.
Поскольку вектор слова "берег" близок к вектору слова "пляж", эта проекция имеет большое значение в категории пляж .

Проецирование вектора слова запроса в пространство категорий
Детали моделирования
Наш классификатор изображений представляет собой сеть EfficientNet, обученную на наборе данных OpenImages. Он выставляет оценки примерно по 8500 категориям. Мы обнаружили, что эта архитектура и набор данных обеспечивают хорошую точность по разумной цене, что имеет значение, если мы хотим обслуживать клиентскую базу размером с Dropbox.
Мы используем TensorFlow для обучения и запуска модели. Мы используем предварительно обученные векторы слов ConceptNet Numberbatch. Это дает хорошие результаты, и, что важно для нас, они поддерживают несколько языков, возвращая одинаковые векторы для слов на разных языках с аналогичным значением. Это упрощает поддержку поиска по содержанию изображений на нескольких языках: векторы слов для dog на английском языке и chien на французском языке похожи, поэтому мы можем поддерживать поиск на обоих языках без необходимости выполнять явное перевод.
Для поиска по нескольким словам мы анализируем запрос как И отдельных слов. Мы также ведем список многословных терминов, таких как пляжный мяч которые можно рассматривать как отдельные слова. Когда запрос содержит один из этих терминов, мы выполняем альтернативный синтаксический анализ и выполняем ИЛИ двух проанализированных запросов — запрос пляжный мяч становится (пляж И мяч) ИЛИ (пляжный мяч) . Он подходит как для больших, красочных, так и для теннисных мячей на песке.
Нецелесообразно получать полную актуальную матрицу J всякий раз, когда пользователь выполняет поиск. Пользователь может иметь доступ к сотням тысяч или даже миллионам изображений, а выходные данные нашего классификатора — это тысячи измерений, поэтому эта матрица может иметь миллиарды записей и должна обновляться всякий раз, когда пользователь добавляет, удаляет или изменяет изображение. Это просто не будет доступно (пока) для сотен миллионов пользователей.
Поэтому вместо создания экземпляра J для каждого запроса мы используем приближение метода, описанного выше, который может быть эффективно реализован в поисковой системе Dropbox Nautilus.
Концептуально Nautilus состоит из прямого индекса, который сопоставляет каждый файл с некоторыми метаданными (например, с именем файла) и полным текстом файла, и перевернутым индексом, который сопоставляет каждое слово со списком сообщений все файлы, содержащие слово. Для текстового поиска содержимое индекса для нескольких файлов рецептов может выглядеть примерно так:

Содержание поискового индекса для текстового поиска
Если пользователь ищет белое вино мы ищем два слова в перевернутом индексе и обнаруживаем, что doc_1 и doc_2 содержат оба слова, поэтому мы должны включить их в результаты поиска. Doc_3 содержит только одно из слов, поэтому мы должны либо опустить его, либо поставить последним в списке результатов.
После того, как мы нашли все документы, которые, возможно, захотим вернуть, мы ищем их в прямом индексе и используем полученную информацию для их ранжирования и фильтрации. В этом случае мы можем поставить doc_1 выше, чем doc_2 потому что два слова встречаются рядом друг с другом.
Переделка методов текстового поиска для поиска изображений
Мы можем использовать эту же систему для реализации нашего алгоритма поиска изображений. В прямом индексе мы можем сохранить вектор пространства категорий j c каждого изображения. В инвертированном индексе для каждой категории мы храним список публикаций изображений с положительными оценками для этой категории.
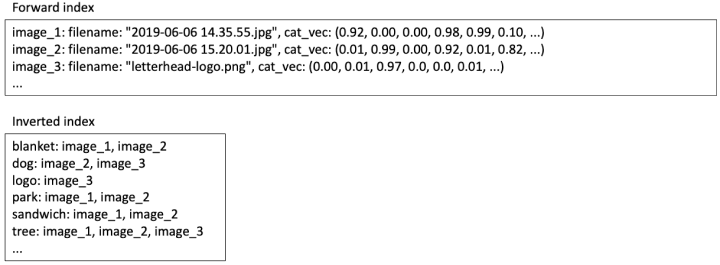
Содержимое индекса поиска для поиска содержимого изображения
Итак, когда пользователь ищет пикник :
- Найдите слово вектор q w для пикник и умножьте на матрицу проекции пространства категорий C чтобы получить q c как описано выше. C — это фиксированная матрица, одинаковая для всех пользователей, поэтому мы можем хранить ее в памяти.
- Для каждой категории с ненулевой записью в q c выберите список сообщений из перевернутого индекса. Объединение этих списков представляет собой набор результатов поиска совпадающих изображений, но эти результаты все равно необходимо ранжировать.
- Для каждого результата поиска выберите вектор пространства категорий j c из прямого индекса и умножьте на q c чтобы получить оценка релевантности s . Возврат результатов с оценкой выше порогового значения, упорядоченной по количеству оценок.
Оптимизация для масштабируемости
Этот подход по-прежнему является дорогостоящим как с точки зрения дискового пространства, так и с точки зрения обработки во время запроса. Если у нас есть 10 000 категорий, то для каждого изображения мы должны хранить 10 000 оценок классификатора в прямом индексе, что составляет 40 килобайт, если мы используем четырехбайтовые значения с плавающей запятой. А поскольку оценки классификатора редко бывают равными нулю, типичное изображение будет добавлено в большинство из этих 10 000 списков сообщений. Если мы используем четырехбайтовые целые числа для идентификаторов изображений, это еще 40 килобайт при стоимости индексации 80 килобайт на изображение. Для многих изображений индексное хранилище будет больше, чем файл изображения!
Что касается обработки во время запроса, которая проявляется как задержка для пользователя, выполняющего поиск, мы можем ожидать, что примерно половина оценок соответствия категории запроса m̂ i будет положительной. , поэтому мы прочитаем около 5000 списков сообщений из перевернутого индекса. Это очень плохо по сравнению с текстовыми запросами, которые обычно читают около десяти списков сообщений.
К счастью, есть много значений, близких к нулю, которые мы можем отбросить, чтобы получить гораздо более эффективное приближение. Оценка релевантности для каждого изображения была дана выше как s = q c j c где q c содержит оценки соответствия между запросом и каждой из примерно 10 000 категорий, а j c содержит примерно 10 000 оценок категорий из классификатора. Оба вектора состоят в основном из значений, близких к нулю, которые вносят очень небольшой вклад в s .
В нашем приближении мы установим все, кроме нескольких самых больших записей q c и j c равными нулю. Экспериментально мы обнаружили, что сохранения 10 первых записей q c и 50 лучших записей j c достаточно для предотвращения ухудшение качества. Значительная экономия на хранении и переработке:
- В прямом индексе вместо 10 000-мерных плотных векторов мы храним разреженные векторы с 50 ненулевыми элементами — 50 лучших оценок категории для каждого изображения. В разреженном представлении мы сохраняем позицию и значение каждой ненулевой записи; Для 50 двухбайтовых целочисленных позиций и 50 четырехбайтовых значений с плавающей запятой требуется около 300 байт.
- В инвертированном индексе каждое изображение добавляется в 50 списков сообщений вместо 10 000, что составляет около 200 байт. Таким образом, общий объем хранилища индекса для каждого изображения составляет 500 байтов вместо 80 килобайт.
- Во время запроса q c имеет 10 ненулевых записей, поэтому нам нужно отсканировать только 10 списков сообщений — примерно такой же объем работы, который мы выполняем для текстовых запросов. Это дает нам меньший набор результатов, который мы также можем получить быстрее.
С такой оптимизацией затраты на индексирование и хранение становятся разумными, а задержки запросов находятся на уровне, аналогичном показателям текстового поиска. Таким образом, когда пользователь инициирует поиск, мы можем выполнять поиск как по тексту, так и по изображениям параллельно и показывать полный набор результатов вместе, не заставляя пользователя ждать дольше, чем при поиске только по тексту.
Поиск графического контента в настоящее время включен для всех пользователей профессионального и бизнес-уровня. Мы объединяем поиск по содержанию изображений для обычных изображений, поиск изображений документов на основе OCR и полнотекстовый поиск по текстовым документам, чтобы сделать большинство файлов этих пользователей доступными с помощью поиска по содержанию.
Поиск видео?
Конечно, мы работаем над тем, чтобы вы могли выполнять поиск по всему вашему контенту Dropbox. Поиск изображений — большой шаг к этому. В конце концов, мы надеемся, что сможем искать и видеоконтент. Методы поиска одного кадра в видео или индексации всего клипа для поиска, возможно, путем адаптации техники неподвижных изображений, все еще находятся на стадии исследования, но всего несколько лет назад «найти все фотографии с моего пикника» с моей собакой в них »работал только в голливудских фильмах.
Наша цель: если он есть в вашем Dropbox, мы найдем его для вас!







