
Обоснованная стратегия ошибок жизненно важна для работоспособности серверных служб. Важно продумать, как обрабатывать ошибку, а если она не может быть обработана, то как ее регистрировать, какая информация полезна для регистрации и кто получает уведомление.
Серверная служба, отвечающая за запуск индивидуальных проектов на 99designs, терпела неудачу для некоторого количества клиентов. К сожалению, из-за множества проблем с существующей стратегией ошибок было трудно получить четкое представление о масштабах возникающих ошибок. Ошибки обрабатывались несколько раз, было много повторяющихся или несущественных ошибок, а зарегистрированные ошибки содержали несогласованные метаданные. Это отсутствие преднамеренной стратегии привело к дрейфу стандартов между кодовыми базами.
Мы потратили некоторое время, исследуя нашу существующую стратегию ошибок и изобретая модель того, как должны работать наши ошибки в наших сервисах Go Twirp. Этот пост дает некоторый контекст об ошибках Go и Twirp, подробности о некоторых проблемах, с которыми мы столкнулись, и излагает нашу стратегию обработки ошибок в будущем.

Стоит упомянуть, что, хотя мы используем Twirp для межсервисной связи, этот совет в равной степени относится к настройкам gRPC или другим фреймворкам RPC, которые используют ошибки Go как часть подписей обработчиков .
Содержание статьи
Справочная информация
—
В 99designs наш план для новых сервисов состоит из небольших двоичных файлов Go, которые обмениваются данными через Twirp либо между собой, либо с нашим интерфейсом через нашу службу агрегирования GraphQL.
Ошибки в Go
Ошибки в Go — это просто ценности. Помимо встроенного интерфейса ошибок, они являются скорее языковым соглашением, чем функцией. По соглашению функция может вернуть ошибку, если произошла ошибка, и вызывающая сторона обязана проверить это значение и предпринять соответствующие действия.
Любой тип может быть ошибкой, если он реализует интерфейс ошибок. Тип ошибки по умолчанию, возвращаемый пакетом ошибок, — это просто строка, содержащая сообщение об ошибке.
Эта модель, в отличие от такой возможности, как «Исключения», заставляет разработчика думать и обрабатывать случаи ошибок в непосредственном контексте вызывающего кода. Наличие этого строгого соглашения также позволяет инструментам легко проверять ошибки и обеспечивать соблюдение передовых практик.
Однако один общий антишаблон, который мы видим в наших сервисах, заключается в том, что когда функция возвращает ошибку, она просто возвращается обратно в стек вызывающей стороне, которая часто может аналогичным образом вернуть ошибку своему собственному вызывающему объекту. В некотором смысле это обратная проблема Исключений; разработчик возвращает ошибку, и мы надеемся, что в стеке есть что-то, что знает, что нужно делать, и исправит ошибку соответствующим образом.
Паника и выздоровление
Другой механизм ошибок Go — это команды panic и recovery. Этот механизм похож на Exception, поскольку выполнение текущей функции останавливается и возвращается к вызывающей стороне. Однако отложенные функции выполняются по мере распространения паники вверх по стеку. Вы можете узнать больше о том, как работают паника и восстановление, в этом сообщении блога.
Ошибка упаковки
Так как ошибки Go — это просто значения, Go не предоставляет в стандартной библиотеке много инструментов для работы с ними. Однако Go 1.13 добавил некоторые утилиты для работы с типичными шаблонами ошибок; специально предоставляя стандартный способ упаковки ошибок в дополнительный контекст, ставший популярным благодаря таким пакетам, как github.com/pkg/errors.
Twirp и ошибки
Twirp — это протокол API protobuf поверх HTTP. Написание Twirp-сервера удобно, потому что разработчик может сосредоточиться на логике обслуживания, а не на проблемах транспорта или маршрутизации; все, что требуется, — это написать определение protobuf и реализовать сгенерированные обработчики RPC. Эти обработчики содержат ошибку в возвращаемом типе, и сервер Twirp пытается преобразовать ошибки, возвращаемые обработчиком, в эквивалентную ошибку HTTP, которая возвращается клиенту.
Twirp определяет ряд полезных типов ошибок, которые отображаются на эквиваленты HTTP. Обработчики также могут возвращать любой допустимый тип ошибки Go, который Twirp будет рассматривать, как если бы это был twirp. Внутренняя ошибка, отображающая ее на ответ HTTP 500. Мы расскажем, что это значит для нашего кода обработчика, в обсуждении ниже.
Багснаг
Bugsnag — это служба отчетов и мониторинга ошибок, которую мы используем. Ошибки можно отправлять в Bugsnag с помощью метода Notify их клиентского пакета Go. Поскольку ошибки Go — это просто значения, интерфейс ошибок не предоставляет методов для получения информации о стеке.
Таким образом, клиент Bugsnag обернет входящую ошибку информацией о стеке с помощью пакета времени выполнения Go и отправит ее вместе с любыми дополнительными метаданными в Bugsnag. Это можно сделать где угодно с помощью пакета github.com/bugsnag/bugsnag-go/errors, а также автоматически при вызове Notify.
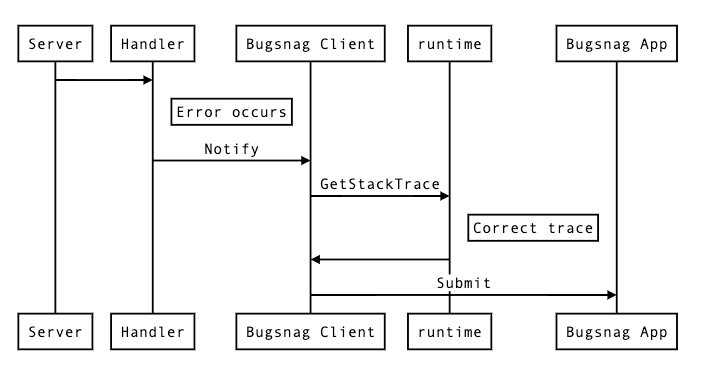
Bugsnag сопоставляет эти ошибки и пытается сгруппировать их так, чтобы вы могли видеть одну и ту же ошибку, сгруппированную вместе. Затем с этими группами могут быть выполнены такие операции, как «игнорировать» или «пометить исправлено».
Подобное построение трассировки стека хорошо работает для обычных вызовов Notify, но терпит неудачу при попытке установить автоматические уведомления в части кода, находящейся за пределами стека, откуда произошла ошибка. Это связано с тем, что группировка по умолчанию в Bugsnag группирует ошибки по 2 метрикам: «типу» ошибки (который Go обычно представляет собой просто строку) и местоположению файла верхнего кадра трассировки стека, отправляемого клиентом. Таким образом, при попытке написать что-то вроде глобального обработчика ошибок информация стека может быть потеряна, и все ошибки могут появиться из того места, откуда в таком обработчике вызывается Notify.
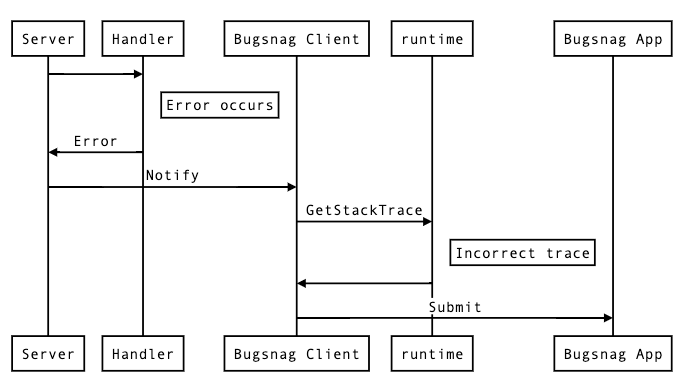
Проблемы с существующей стратегией ошибок
—
Помня об этом контексте, давайте рассмотрим некоторые из распространенных проблем, с которыми мы столкнулись в наших сервисах Go Twirp при нашей существующей стратегии ошибок.
Обработчики Twirp, возвращающие ошибки
Как упоминалось ранее, сгенерированные интерфейсы Twirp ожидают ответного сообщения и ошибки от функции обработчика. Любая ошибка, которая не вводится с кодом ошибки Twirp, упаковывается во внутреннюю ошибку Twirp и обрабатывается как ошибка сервера.
Это может быть проблемой в случае ошибки самого запроса. Примером может быть попытка получить несуществующую запись, попытку выполнить недопустимое действие или неверно сформированный текст запроса. Это ошибки, которые вызваны клиентской стороной, поэтому рассмотрение их как внутренней ошибки сервера не означает, что клиент несет ответственность за проблему.
Возвращенные ошибки также передаются обратно клиенту и могут привести к случайной утечке информации, к которой клиент в противном случае не имел бы доступа.
Индивидуальные вызовы для уведомления об ошибках Bugsnag
Из-за отсутствия какого-либо кода автоматической обработки ошибок более высокого уровня разработчики вынуждены размещать специальные вызовы для уведомления Bugsnag в тех местах, где, по их мнению, они могут столкнуться с ошибкой.
У этого подхода есть ряд проблем. Во-первых, это непоследовательно, и вы не можете получить полное представление обо всех ошибках, возникающих на вашей платформе. Ошибки регистрируются только в тех местах, которые разработчик не забывает вызывать Notify.
Во-вторых, если вы не отключите обработчик на месте, вы рискуете отправить уведомление об ошибке несколько раз. Это может создать путаницу при просмотре ошибок, поскольку несколько уведомлений имеют один и тот же источник.
Неправильные следы стека
Сгенерированный сервер Twirp предоставляет перехватчики для запуска кода, когда от обработчика возвращается ошибка. Изначально это кажется идеальным местом для выполнения автоматического вызова Notify, однако помните, что ошибки Go не имеют связанной с ними информации стека. Напомним также, что Bugsnag группирует ошибки по последнему кадру стека.
Автоматический вызов Notify будет иметь одну и ту же трассировку стека для всех ошибок, и поэтому все ошибки будут сгруппированы вместе в интерфейсе Bugsnag, что означает, что массовые действия не могут выполняться с подмножествами ошибок.
Отсутствие контекста для возвращаемых ошибок
При возврате ошибки из функции часто важно, чтобы к ошибке был добавлен контекст, чтобы либо вызывающий, либо разработчик, читающий ошибку, лучше понимал возникшую ошибку.
Однако многие существующие вызовы этого не делают и возвращают исходную ошибку обратно вызывающей стороне. Это приводит к утечке деталей реализации, и может быть трудно отследить фактическое состояние ошибки.
Лучшая стратегия ошибок
—
Наши микросервисы Go достаточно малы, чтобы можно было достичь нулевого уровня входящих сообщений в Bugsnag; все ошибки следует либо игнорировать, потому что они не важны, либо требовать внимания разработчика, и их следует помещать в журнал, исправлять, а затем отмечать как устраненные. Добраться до этого момента чрезвычайно полезно, поскольку это означает, что инженер может своевременно исследовать любую ошибку, о которой сообщила служба.
На практике достичь этого может быть сложно, но мы приняли некоторые из следующих стратегий, пытаясь достичь этого идеального сценария.
Общая обработка ошибок Go
Когда ошибка возникает в общем коде Go, простой возврат ошибки не всегда может быть лучшим способом действий. Подумайте о том, чтобы добавить к ошибке дополнительный контекст, если он поможет вызывающей стороне понять, что произошло, используя заполнитель Go 1.13 % w с fmt.Errorf.
func doOperation () error {
ошибка: = callService ()
if err! = nil {
return fmt.Errorf ("операция не удалась:% w", ошибка)
}
}
Панику следует использовать с осторожностью в инвариантных случаях, когда ситуация никогда не должна быть возможной. Паника указывает на то, что функция не считает, что возвращение значения ошибки было бы полезным для вызывающей стороны. В этих случаях, вероятно, потребуется внести исправление от разработчика.
Явные вызовы Notify по-прежнему можно использовать, но их следует использовать только в ситуациях, когда разработчик хочет знать, что возникла ситуация, которую еще можно исправить.
Ошибки упаковки
Перед возвратом ошибки следует заключить в оболочку, если функция может добавить полезный контекст с более конкретным сообщением об ошибке или хочет украсить ошибку дополнительными метаданными. Полезный контекст может включать информацию о связанных объектах домена или связанных структурированных данных, которые вызывающий может использовать для помощи в обработке ошибки.
Автоматическое уведомление об ошибках
Таким образом, чтобы решить проблемы с помощью специальных вызовов Notify, нам нужен автоматический способ уведомления Bugsnag при возникновении ошибки, которая, по нашему мнению, требует внимания разработчика. И нам нужно сделать это таким образом, чтобы он сохранял полезную трассировку стека и правильно группировался в Bugsnag.
Наше решение состоит в том, чтобы установить обработчик паники высоко в стеке из приложения, которое может восстанавливаться, и автоматически вызывать Bugsnag с ошибкой. Преимущество использования паники заключается в том, что стек сохраняется для всех вызовов defer, и поэтому можно построить точную трассировку стека с точки паники.
func BugsnagMiddleware (w http.ResponseWriter, r * http.Request) {
defer func () {
если p: = recovery (); p! = nil {
ошибка: = NewErrorWithStackTrace (p)
bugsnag.Notify (r.Context (), ошибка)
}
} ()
next.ServeHTTP (w, r)
}
В этом примере NewErrorWithStackTrace вызывает среду выполнения go, чтобы получить текущий стек, и удаляет достаточно кадров сверху, пока верхний кадр стека не станет местоположением исходной паники. Урезанная версия этой функции может выглядеть так:
func NewErrorWithStackTrace (p interface {}) * Error {
кадры: = GetStackFrames ()
lastPanic: = 0
для i, frame: = range frames {
если frame.Func (). Name () == "runtime.gopanic" {
lastPanic = я
}
}
ret.frames = ret.frames [lastPanic+1:]
возврат & Ошибка {err, frames}
}
Мы добавляем эту информацию о стеке к настраиваемому типу ошибки, который соответствует интерфейсу ErrorWithStackFrames, предоставляемому клиентом Bugsnag.
Обработчики Twirp
Ошибки, которые всплывают в обработчике Twirp, обычно попадают в одну из двух категорий: клиентские ошибки, где ошибка связана с запросом и должна обрабатываться вызывающей стороной. И ошибки сервера, в которых виновата подчиненная служба.
1. Ошибки клиента
Эквивалент коду состояния диапазона HTTP 400. Ответственность за эти ошибки несет клиент. Ошибки аутентификации и авторизации попадают в эту категорию, как и ошибки проверки. Другие примеры включают неправильные запросы, недопустимые аргументы или ресурсы, которые не могут быть обнаружены.
Они должны быть возвращены обработчиком с использованием соответствующих кодов ошибок twirp. Пример:
err: = json.Unmarshal ([] байт (req.JSONBlob), & dst)
if err! = nil {
return nil, twirp.NewError (twirp.Malformed, fmt.Sprintf ("не удалось демаршалировать запрос:% v", err))
}
Ошибки проверки
Некоторые проблемы, такие как проверка, требуют, чтобы метаданные возвращались с ошибками. Есть два основных способа реализовать это дело.
Первый — просто включить его как часть ответного сообщения. Само ответное сообщение может указывать, был ли запрос успешным, а если нет, какие ошибки были обнаружены. Это полезно для сценариев проверки, когда клиент может захотеть отобразить обнаруженные ошибки для конечного пользователя, и с каждой ошибкой могут быть связаны некоторые дополнительные метаданные.
Другая реализация заключается в использовании карты метаданных ошибок Twirp — простой карты ключ / значение, которая является функцией ошибок Twirp и доступна для чтения на клиенте.
У нас нет сильных рекомендаций, возможно, потребуется некоторое суждение. Нам интересно услышать, как разработчики нашли опыт работы с каждым случаем.
2. Ошибки сервера
Ошибка сервера — это любая ошибка, которая возникает не из-за входящего запроса, а по любой другой причине, которую клиент не может предсказать. Эти ошибки считаются неисправимыми и поэтому должны вызывать панику внутри самого обработчика. Пример:
err: = db.Insert (запись)
if err! = nil {
panic (fmt.Errorf ("не удалось выполнить вставку в базу данных:% w", ошибка))
}
Эти ошибки будут обнаружены обработчиком паники верхнего уровня и трассировкой стека, созданной на этом этапе, как описано выше.
В некоторых случаях ошибка сервера все еще может возникать, но по какой-то причине ее ожидают. Эти случаи не требуют рассмотрения разработчиком. В таких случаях может быть возвращена любая ошибка, и клиент получит 500, однако уведомление об ошибке не будет отправлено.
Стоит отметить, что интерфейс стандартной библиотеки http.Handler не предоставляет возвращаемое значение ошибки в подписи ServeHTTP. Это лучший дизайн, поскольку он заставляет обработчик вызывать панику в случае возникновения необработанной ошибки. Имея отдельный канал для ошибок, Twirp (и расширение grpc) дает пользователям возможность просто возвращать ошибки, которые они вызывают, вместо того, чтобы применять продуманный подход на основе каждой ошибки.
Заключение
—
Хотя эта тема на первый взгляд может показаться скучной, распаковка на самом деле является сложной и требует внимательного рассмотрения. Преднамеренная обработка ошибок может помочь командам понять проблемы, с которыми сталкивается служба, а также быстро определить приоритеты и решить проблемы по мере их возникновения.
Хорошая стратегия обработки ошибок содержит четкие рекомендации, определяющие шаблоны, которые разработчики могут использовать для обработки распространенных вариантов использования. Хотя эти шаблоны могут не подходить для всех сценариев, они поучительны и помогают лучше информировать разработчиков о том, как выглядит хорошая обработка ошибок.
В данном конкретном случае, после принятия этой стратегии, мы смогли четко определить объем затронутых таможен и проблемы, с которыми они сталкивались. Это позволило нам расставить приоритеты по исправлению типичных проблем и позволить нам постоянно доверять сообщениям об ошибках.
В дальнейшем мы намерены внедрить этот шаблон во всех наших сервисах и, надеюсь, добраться до места, где наши серверные модули будут информировать нас, когда что-то идет не так, и мы сможем быстро отреагировать.







